Java Collection Framework
The collections framework is extensive, and powerful.
Collection
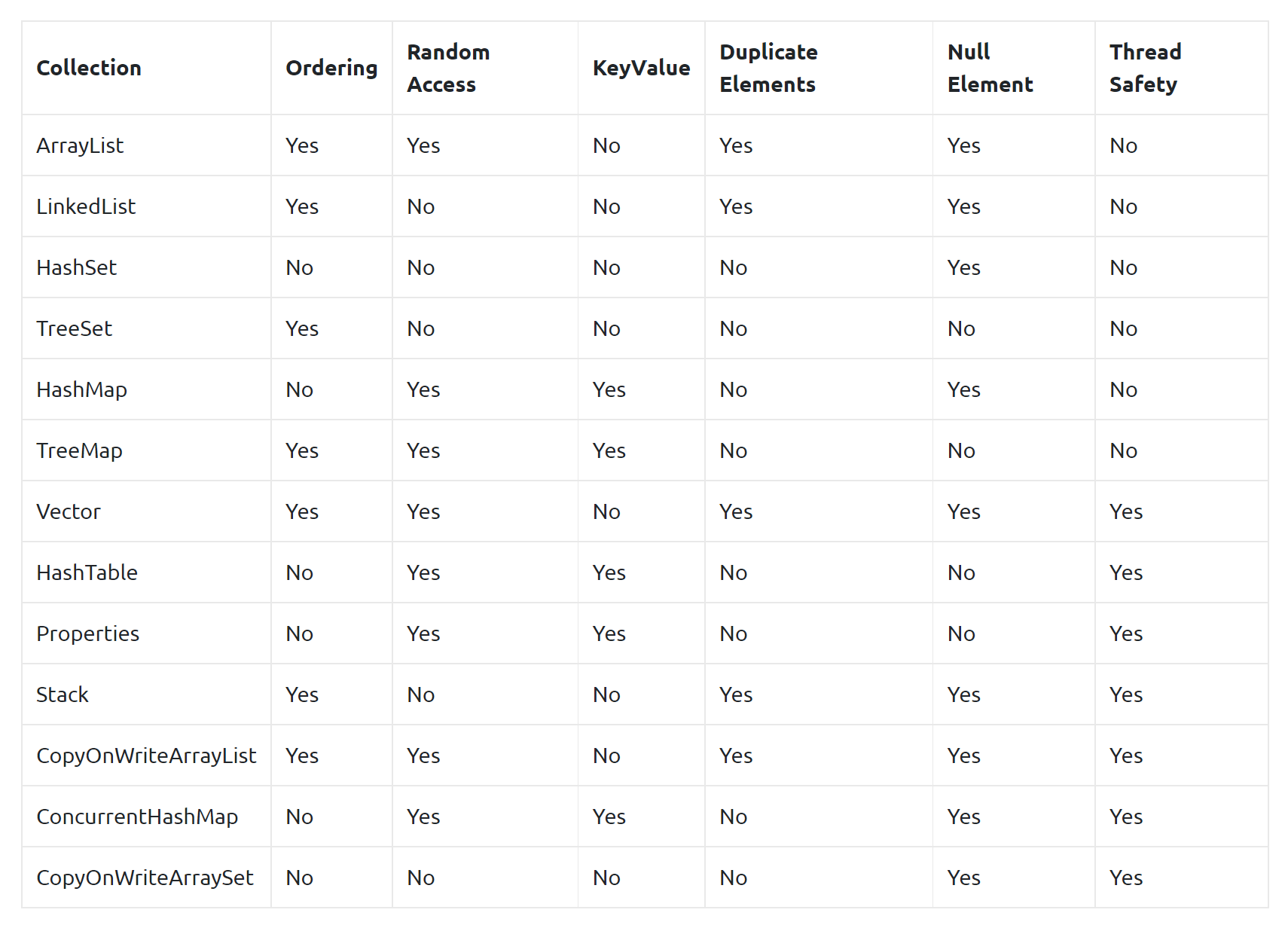
List
In Java, the List interface is a part of the Java Collections Framework. It is a subinterface of the Collection interface and represents an ordered collection of objects, where elements can be inserted or accessed by their position in the list. The List interface provides a way to store and retrieve elements in a specific order, and allows duplicate elements.
Some of the key methods provided by the List interface include:
- add(E element): Adds the specified element to the end of the list.
- add(int index, E element): Inserts the specified element at the specified position in the list.
- get(int index): Returns the element at the specified position in the list.
- remove(int index): Removes the element at the specified position in the list.
- set(int index, E element): Replaces the element at the specified position in the list with the specified element.
- size(): Returns the number of elements in the list.
Java provides several implementations of the List interface, such as ArrayList, LinkedList, and Vector. ArrayList is the most commonly used implementation of the List interface, which stores elements in a dynamic array and can be used when the size of the list is expected to change frequently. LinkedList stores elements in a doubly-linked list and is useful when frequent insertion or deletion is expected. Vector is similar to ArrayList but is synchronized, which means it can be used in a multi-threaded environment.
It's important to note that, the List interface allows for random access to its elements via their index, the time complexity of a random access is O(1).
The List interface provides a special iterator, called a ListIterator, that allows element insertion and replacement, and bidirectional access in addition to the normal operations that the Iterator interface provides. A method is provided to obtain a list iterator that starts at a specified position in the list.
ArrayList
An ArrayList in Java represents a resizable list of objects. We can add, remove, find, sort and replace elements in this list.
ArrayList is the part of the collections framework. It extends AbstractList which implements List interface. The List extends Collection and Iterable interfaces in hierarchical order.
An array is fixed size data structure where the size has to be declared during initialization. Once the size of an array is declared, it is not possible to resize the array without creating a new array.
The ArrayList offers to remove this sizing limitation. An ArrayList can be created with any initial size (default 16), and when we add more items, the size of the arraylist grows dynamically without any intervention by the programmer.
ArrayList has the following features –
I. Ordered – Elements in arraylist preserve their ordering which is by default the order in which they were added to the list.
II. Index based – Elements can be randomly accessed using index positions. Index start with '0'.
III. Dynamic resizing – ArrayList grows dynamically when more elements needs to be added than it’s current size.
IV. Non synchronized – ArrayList is not synchronized, by default. Programmer needs to use synchronized keyword appropiately or simply use Vector class.
V. Duplicates allowed – We can add duplicate elements in arraylist. It is not possible in sets.
Ex:
ArrayList<Integer> numList = new ArrayList<>();
ArrayList<String> charList = new ArrayList<>(Arrays.asList(("A", "B", "C"));
String aChar = alphabetsList.get(0);
Iterate arraylist
====================
ArrayList<Integer> digits = new ArrayList<>(Arrays.asList(1,2,3,4,5,6));
Iterator<Integer> iterator = digits.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
Iterate arraylist with for loop
===============================
ArrayList<Integer> digits = new ArrayList<>(Arrays.asList(1,2,3,4,5,6));
for(int i = 0; i < digits.size(); i++) {
System.out.print(digits.get(i));
}
Merge two ArrayLists without duplicate elements:
===============================================
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Set;
public class ArrayListExample {
public static void main(String[] args) throws Exception {
ArrayList<String> listOne = new ArrayList<>(Arrays.asList("a", "b", "c", "d", "e"));
ArrayList<String> listTwo = new ArrayList<>(Arrays.asList("a", "b", "c", "f", "g"));
//1
Set<String> set = new LinkedHashSet<>(listOne);
set.addAll(listTwo);
List<String> combinedList = new ArrayList<>(set);
System.out.println(combinedList);
//2
List<String> listTwoCopy = new ArrayList<>(listTwo);
listTwoCopy.removeAll(listOne);
listOne.addAll(listTwoCopy);
System.out.println(listOne);
}
}
Merge arraylists example with Java 8 stream API
================================================
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class ArrayListExample {
public static void main(String[] args) throws Exception {
ArrayList<String> listOne = new ArrayList<>(Arrays.asList("a", "b", "c", "d", "e"));
ArrayList<String> listTwo = new ArrayList<>(Arrays.asList("a", "b", "c", "f", "g"));
List<String> combinedList = Stream.of(listOne, listTwo)
.flatMap(x -> x.stream())
.collect(Collectors.toList());
System.out.println(combinedList);
}
}
LinkedList
Java LinkedList class is doubly-linked list implementation of the List and Deque interfaces. It implements all optional list operations, and permits all elements (including null).
LinkedListExample examples
==========================
import java.util.LinkedList;
import java.util.ListIterator;
public class LinkedListExample {
public static void main(String[] args) {
//Create linked list
LinkedList<String> linkedList = new LinkedList<>();
//Add elements
linkedList.add("A");
linkedList.add("B");
linkedList.add("C");
linkedList.add("D");
System.out.println(linkedList);
//Add elements at specified position
linkedList.add(4, "A");
linkedList.add(5, "A");
System.out.println(linkedList);
//Remove element
linkedList.remove("A"); //removes A
linkedList.remove(0); //removes B
System.out.println(linkedList);
//Iterate
ListIterator<String> itrator = linkedList.listIterator();
while (itrator.hasNext()) {
System.out.println(itrator.next());
}
}
}
LinkedList Sort Example
========================
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("A");
linkedList.add("C");
linkedList.add("B");
linkedList.add("D");
//Unsorted
System.out.println(linkedList);
//1. Sort the list
Collections.sort(linkedList);
//Sorted
System.out.println(linkedList);
//2. Custom sorting
Collections.sort(linkedList, Collections.reverseOrder());
//Custom sorted
System.out.println(linkedList);
LinkedList Features
I. Doubly linked list implementation which implements List and Deque interfaces. Therefore, It can also be used as a Queue, Deque or Stack.
II. Permits all elements including duplicates and NULL.
III. LinkedList maintains the insertion order of the elements.
IV. It is not synchronized. If multiple threads access a linked list concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally.
V. Use Collections.synchronizedList(new LinkedList()) to get synchronized linkedlist.
VI. The iterators returned by this class are fail-fast and may throw ConcurrentModificationException.
VII. It does not implement RandomAccess interface. So we can access elements in sequential order only. It does not support accessing elements randomly.
VIII. We can use ListIterator to iterate LinkedList elements.
LinkedList Performance
In Java LinkedList class, manipulation is fast because no shifting needs to be occurred. So essentially, all add and remove method provide very good performance O(1).
add(E element) method is of O(1).
get(int index) and add(int index, E element) methods are of O(n).
remove(int index) method is of O(n).
Iterator.remove() is O(1).
ListIterator.add(E element) is O(1).
LinkedList should be preferred there are no large number of random access of element while there are a large number of add/remove operations
ArrayList vs LinkedList
Let’s list down few notiable differences between arraylist and linkedlist.
- ArrayList is implemented with the concept of dynamic resizable array. While LinkedList is a doubly linked list implementation.
- ArrayList allows random access to it’s elements while LinkedList does not.
- LinkedList, also implements Queue interface which adds more methods than ArrayList, such as offer(), peek(), poll(), etc.
- While comparing to LinkedList, ArrayList is slower in add and remove, but faster in get, because there is no need of resizing array and copying content to new array if array gets full in LinkedList.
- LinkedList has more memory overhead than ArrayList because in ArrayList each index only holds actual object but in case of LinkedList each node holds both data and address of next and previous node.
Set
Sets represents a collection of sorted elements.
A collection that contains no duplicate elements. More formally, sets contain no pair of elements e1 and e2 such that e1.equals(e2), and at most one null element. As implied by its name, this interface models the mathematical set abstraction.
HashSet
Java HashSet class implements the Set interface, backed by a hash table(actually a HashMap instance). If does not offer any guarantees as to the iteration order, and allows null element.
HashSet Features
- It implements Set Interface.
- Duplicate values are not allowed in HashSet.
- One NULL element is allowed in HashSet.
- It is un-ordered collection and makes no guarantees as to the iteration order of the set.
- This class offers constant time performance for the basic operations(add, remove, contains and size).
- HashSet is not synchronized. If multiple threads access a hash set concurrently, and at least one of the threads modifies the set, it must be synchronized externally.
- Use Collections.synchronizedSet(new HashSet()) method to get the synchronized hashset.
- The iterators returned by this class’s iterator method are fail-fast and may throw ConcurrentModificationException if the set is modified at any time after the iterator is created, in any way except through the iterator’s own remove() method.
- HashSet also implements Searlizable and Cloneable interfaces.
Load Factor
The load factor is a measure of how full the HashSet is allowed to get before its capacity is automatically increased. Default load factor is 0.75.
This is called threshold and is equal to (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY). When HashSet elements count exceed this threshold, HashSet is resized and new capacity is double the previous capacity.
With default HashSet, the internal capacity is 16 and the load factor is 0.75. The number of buckets will automatically get increased when the table has 12 elements in it.
Java HashSet Example
====================
//1. Create HashSet
HashSet<String> hashSet = new HashSet<>();
//2. Add elements to HashSet
hashSet.add("A");
hashSet.add("B");
hashSet.add("C");
hashSet.add("D");
hashSet.add("E");
System.out.println(hashSet);
//3. Check if element exists
boolean found = hashSet.contains("A"); //true
System.out.println(found);
//4. Remove an element
hashSet.remove("D");
//5. Iterate over values
Iterator<String> itr = hashSet.iterator();
while(itr.hasNext()) {
String value = itr.next();
System.out.println("Value: " + value);
}
Convert HashSet to ArrayList
=============================
HashSet<String> hashSet = new HashSet<>();
hashSet.add("A");
hashSet.add("B");
hashSet.add("C");
hashSet.add("D");
hashSet.add("E");
List<String> valuesList = hashSet.stream().collect(Collectors.toList());
System.out.println(valuesList);
TreeSet
Java TreeSet class extends AbstractSet and implements NavigableSet interface. It is very similar to HashSet class, except it stores the element in sorted order.
The sort order is either natural order or by a Comparator provided at treeset creation time, depending on which constructor is used.
TreeSet Features
- It extends AbstractSet class which extends AbstractCollection class.
- It implements NavigableSet interface which extends SortedSet interface.
- Duplicate values are not allowed in TreeSet.
- NULL is not allowed in TreeSet.
- It is an ordered collection which store the elements in sorted order.
- Like HashSet, this class offers constant time performance for the basic operations(add, remove, contains and size).
- TreeSet does not allow to insert heterogeneous objects because it must compare objects to determine sort order.
- TreeSet is not synchronized. If multiple threads access a hash set concurrently, and at least one of the threads modifies the set, it must be synchronized externally.
- Use Collections.synchronizedSortedSet(new TreeSet()) method to get the synchronized TreeSet.
- The iterators returned by this class’s iterator method are fail-fast and may throw ConcurrentModificationException if the set is modified at any time after the iterator is created, in any way except through the iterator’s own remove() method.
- TreeSet also implements Searlizable and Cloneable interfaces.
Java TreeSet Example
====================
//1. Create TreeSet
TreeSet<String> TreeSet = new TreeSet<>();
//2. Add elements to TreeSet
TreeSet.add("A");
TreeSet.add("B");
TreeSet.add("C");
TreeSet.add("D");
TreeSet.add("E");
System.out.println(TreeSet);
//3. Check if element exists
boolean found = TreeSet.contains("A"); //true
System.out.println(found);
//4. Remove an element
TreeSet.remove("D");
//5. Iterate over values
Iterator<String> itr = TreeSet.iterator();
while(itr.hasNext()) {
String value = itr.next();
System.out.println("Value: " + value);
}
LinkedHashSet
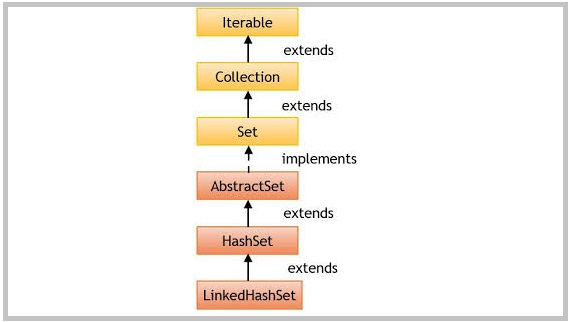
Java LinkedHashSet class extends HashSet and implements Set interface. It is very very similar to HashSet class, except if offers the predictable iteration order.
LinkedHashSet Features
- It extends HashSet class which extends AbstractSet class.
- It implements Set interface.
- Duplicate values are not allowed in LinkedHashSet.
- One NULL element is allowed in LinkedHashSet.
- It is an ordered collection which is the order in which elements were inserted into the set (insertion-order).
- Like HashSet, this class offers constant time performance for the basic operations(add, remove, contains and size).
- LinkedHashSet is not synchronized. If multiple threads access a hash set concurrently, and at least one of the threads modifies the set, it must be synchronized externally.
- Use Collections.synchronizedSet(new LinkedHashSet()) method to get the synchronized LinkedHashSet.
- The iterators returned by this class’s iterator method are fail-fast and may throw ConcurrentModificationException if the set is modified at any time after the iterator is created, in any way except through the iterator’s own remove() method.
- LinkedHashSet also implements Searlizable and Cloneable interfaces.
Java LinkedHashSet Example
===========================
//1. Create LinkedHashSet
LinkedHashSet<String> LinkedHashSet = new LinkedHashSet<>();
//2. Add elements to LinkedHashSet
LinkedHashSet.add("A");
LinkedHashSet.add("B");
LinkedHashSet.add("C");
LinkedHashSet.add("D");
LinkedHashSet.add("E");
System.out.println(LinkedHashSet);
//3. Check if element exists
boolean found = LinkedHashSet.contains("A"); //true
System.out.println(found);
//4. Remove an element
LinkedHashSet.remove("D");
//5. Iterate over values
Iterator<String> itr = LinkedHashSet.iterator();
while(itr.hasNext()) {
String value = itr.next();
System.out.println("Value: " + value);
}
Map
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value. This interface takes the place of the Dictionary class, which was a totally abstract class rather than an interface.
The Map interface provides three collection views, which allow a map's contents to be viewed as a set of keys, collection of values, or set of key-value mappings. The order of a map is defined as the order in which the iterators on the map's collection views return their elements. Some map implementations, like the TreeMap class, make specific guarantees as to their order; others, like the HashMap class, do not.
HashMap
HashMap in Java in a collection class which implements Map interface. It is used to store key & value pairs. Each key is mapped to a single value in the map.
Keys are unique. It means we can insert a key ‘K’ only once in a map. Duplicate keys are not allowed. Though a value 'V' can be mapped to multiple keys.
HashMap works on principle of hashing. Hashing is a way to assigning a unique code for any variable/object after applying any formula/algorithm on its properties. Each object in java has it’s hash code in such a way that two equal objects must produce the same hash code consistently.
Java HashMap Features
- HashMap cannot contain duplicate keys.
- HashMap allows multiple null values but only one null key.
- HashMap is an unordered collection. It does not guarantee any specific order of the elements.
- HashMap is not thread-safe. You must explicitly synchronize concurrent modifications to the HashMap. Or you can use Collections.synchronizedMap(hashMap) to get the synchronized version of HashMap.
- A value can be retrieved only using the associated key.
- HashMap stores only object references. So primitives must be used with their corresponding wrapper classes. Such as int
- will be stored as Integer.
- HashMap implements Cloneable and Serializable interfaces.
Internal working All instances of Entry class are stored in an array declard as 'transient Entry[] table'. For each key-value to be stored in HashMap, a hash value is calculated using the key’s hash code. This hash value is used to calculate the index in the array for storing Entry object.
In case of collision, where multiple keys are mapped to single index location, a linked list of formed to store all such key-value pairs which should go in single array index location.
While retrieving the value by key, first index location is found using key’s hashcode. Then all elements are iterated in the linkedlist and correct value object is found by identifying the correct key using it’s equals() method.
HashMap Example
=================
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) throws CloneNotSupportedException {
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map);
}
}
HashTable
Java Hashtable class is an implementation of hash table data structure. It is very much similar to HashMap in Java, with most significant difference that Hashtable is synchronized while HashMap is not.
How Hashtable Works? Hashtable internally contains buckets in which it stores the key/value pairs. The Hashtable uses the key’s hashcode to determine to which bucket the key/value pair should map.

The function to get bucket location from Key’s hashcode is called hash function. In theory, a hash function is a function which when given a key, generates an address in the table. A hash function always returns a number for an object. Two equal objects will always have the same number while two unequal objects might not always have different numbers.
When we put objects into a hashtable, it is possible that different objects (by the equals() method) might have the same hashcode. This is called a collision. To resolve collisions, hashtable uses an array of lists. The pairs mapped to a single bucket (array index) are stored in a list and list reference is stored in array index.
Hashtable Features
The important things to learn about Java Hashtable class are:
- It is similar to HashMap, but it is synchronized while HashMap is not synchronized.
- It does not accept null key or value.
- It does not accept duplicate keys.
- It stores key-value pairs in hash table data structure which internally maintains an array of list. Each list may be referred as a bucket. In case of collisions, pairs are stored in this list.
- Enumerator in Hashtable is not fail-fast.
Hashtable Example
=================
import java.util.Hashtable;
import java.util.Iterator;
public class HashtableExample {
public static void main(String[] args) {
//1. Create Hashtable
Hashtable<Integer, String> hashtable = new Hashtable<>();
//2. Add mappings to hashtable
hashtable.put(1, "A");
hashtable.put(2, "B" );
hashtable.put(3, "C");
System.out.println(hashtable);
//3. Get a mapping by key
String value = hashtable.get(1); //A
System.out.println(value);
//4. Remove a mapping
hashtable.remove(3); //3 is deleted
//5. Iterate over mappings
Iterator<Integer> itr = hashtable.keySet().iterator();
while(itr.hasNext()) {
Integer key = itr.next();
String mappedValue = hashtable.get(key);
System.out.println("Key: " + key + ", Value: " + mappedValue);
}
}
}
Hashtable vs HashMap
Let’s quickly list down the differences between a hashmap and hashtable in Java.
HashMap is non synchronized. Hashtable is synchronized.
HashMap allows one null key and multiple null values. Hashtable doesn’t allow any null key or value.
HashMap is fast. Hashtable is slow due to added synchronization.
HashMap is traversed by Iterator. Hashtable is traversed by Enumerator and Iterator.
Iterator in HashMap is fail-fast. Enumerator in Hashtable is not fail-fast.
HashMap inherits AbstractMap class. Hashtable inherits Dictionary class.
TreeMap
TreeMap in Java is used to store key-value pairs very similar to HashMap class. Difference is that TreeMap provides an efficient way to store key/value pairs in sorted order. It is a red-Black tree based NavigableMap implementation.
TreeMap Features
The important points about Java TreeMap class are:
- It stores key-value pairs similar to like HashMap.
- It allows only distinct keys. Duplicate keys are not possible.
- It cannot have null key but can have multiple null values.
- It stores the keys in sorted order (natural order) or by a Comparator provided at map creation time.
- It provides guaranteed log(n) time cost for the containsKey, get, put and remove operations.
- It is not synchronized. Use Collections.synchronizedSortedMap(new TreeMap()) to work in concurrent environment.
- The iterators returned by the iterator method are fail-fast.
TreeMap examples
================
import java.util.Iterator;
import java.util.TreeMap;
public class LinkedHashMapExample {
public static void main(String[] args) {
//Natual ordering by deafult
TreeMap<Integer, String> pairs = new TreeMap<>();
pairs.put(2, "B");
pairs.put(1, "A");
pairs.put(3, "C");
String value = pairs.get(3); //get method
System.out.println(value);
value = pairs.getOrDefault(5, "oops"); //getOrDefault method
System.out.println(value);
//Iteration example
Iterator<Integer> iterator = pairs.keySet().iterator();
while(iterator.hasNext()) {
Integer key = iterator.next();
System.out.println("Key: " + key + ", Value: " + pairs.get(key));
}
//Remove example
pairs.remove(3);
System.out.println(pairs);
System.out.println(pairs.containsKey(1)); //containsKey method
System.out.println(pairs.containsValue("B")); //containsValue method
System.out.println(pairs.ceilingKey(2));
}
}
Concurrency in TreeMap
Both versions of Map, HashMap and TreeMap aren’t synchronized and the programmer need to manage concurrent access on the maps.
We can get the synchronized view of the treemap explicitly using Collections.synchronizedSortedMap(new TreeMap()).
LinkedHashMap
LinkedHashMap in Java is used to store key-value pairs very similar to HashMap class. Difference is that LinkedHashMap maintains the order of elements inserted into it while HashMap is unordered.
LinkedHashMap Features
The important things to learn about Java LinkedHashMap class are:
- It stores key-value pairs similar to HashMap.
- It contains only unique keys. Duplicate keys are not allowed.
- It may have one null key and multiple null values.
- It maintains the order of K,V pairs inserted to it by adding elements to internally managed doubly-linked list.
LinkedHashMap examples
======================
import java.util.Iterator;
import java.util.LinkedHashMap;
public class LinkedHashMapExample {
public static void main(String[] args) {
//3rd parameter set access order
LinkedHashMap<Integer, String> pairs = new LinkedHashMap<>();
pairs.put(1, "A");
pairs.put(2, "B");
pairs.put(3, "C");
String value = pairs.get(3); //get method
System.out.println(value);
value = pairs.getOrDefault(5, "oops"); //getOrDefault method
System.out.println(value);
//Iteration example
Iterator<Integer> iterator = pairs.keySet().iterator();
while(iterator.hasNext()) {
Integer key = iterator.next();
System.out.println("Key: " + key + ", Value: " + pairs.get(key));
}
//Remove example
pairs.remove(3);
System.out.println(pairs);
System.out.println(pairs.containsKey(1)); //containsKey method
System.out.println(pairs.containsValue("B")); //containsValue method
}
}
Concurrency in LinkedHashMap
Both HashMap and LinkedHashMap are not thread-safe which means we can not directly use them in a multi-threaded application for consistent results. We should synchronize them explicitely by using Collections.synchronizedMap(Map map) method.
Map<Integer, Integer> numbers = Collections.synchronizedMap(new LinkedHashMap<>());
Map<Integer, Integer> numbers = Collections.synchronizedMap(new HashMap<>());
Concurrent HashMap
Concurrent HashMap is part of concurrent collection classes. It allow us to modify the map while iterating and operations are thread safe. It wont allow null for keys and values.
If you modify the map while itrating we will get ConcurrentModificationException but with concurrent hash map we wont see that exception.
//ConcurrentHashMap
Map<String,String> myMap = new ConcurrentHashMap<String,String>();
myMap.put("1", "1");
myMap.put("2", "1");
myMap.put("3", "1");
myMap.put("4", "1");
myMap.put("5", "1");
myMap.put("6", "1");
System.out.println("ConcurrentHashMap before iterator: "+myMap);
Iterator<String> it = myMap.keySet().iterator();
while(it.hasNext()){
String key = it.next();
if(key.equals("3")) myMap.put(key+"new", "new3");
}
System.out.println("ConcurrentHashMap after iterator: "+myMap);
equals() and hashCode() Methods
hashCode() and equals() methods have been defined in Object class which is parent class for java objects. For this reason, all java objects inherit a default implementation of these methods.
hashCode() method is used to get a unique integer for given object. This integer is used for determining the bucket location, when this object needs to be stored in some HashTable like data structure. By default, Object’s hashCode() method returns and integer representation of memory address where object is stored. equals() method, as name suggest, is used to simply verify the equality of two objects. Default implementation simply check the object references of two objects to verify their equality.
Note that it is generally necessary to override the hashCode method whenever this method is overridden, so as to maintain the general contract for the hashCode() method, which states that equal objects must have equal hash codes.
equals() must define an equality relation (it must be reflexive, symmetric and transitive). In addition, it must be consistent (if the objects are not modified, then it must keep returning the same value). Furthermore, o.equals(null) must always return false.
hashCode() must also be consistent (if the object is not modified in terms of equals(), it must keep returning the same value). The relation between the two methods is:
Whenever a.equals(b) then a.hashCode() must be same as b.hashCode().
@Override
public String toString() {
return "index [" + index +" ] type [ "+ type + "]";
}
@override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + index;
result = prime * result + type;
result = prime * result +((value == null)? 0 : value.hashCode())
return result;
}
@Override
public boolean equals(Object obj) {
if(this == obj) {
return true;
} if(this == null) {
return false;
} if(getClass() != obj.getClass()) {
return false;
}
final TestClass other = (TestClass) Obj;
if(index != other.index) {
return false;
} if(type != other.type) {
return false;
}
return true;
Create immutable class in Java
n immutable class is one whose state can not be changed once created. Here, state of object essentially means the values stored in instance variable in class whether they are primitive types or reference types.
To make a class immutable, below steps needs to be followed:
- Don’t provide “setter” methods or methods that modify fields or objects referred to by fields. Setter methods are meant to change the state of object and this is what we want to prevent here.
- Make all fields final and private. Fields declared private will not be accessible outside the class and making them final will ensure the even accidentally you can not change them.
- Don’t allow subclasses to override methods. The simplest way to do this is to declare the class as final. Final classes in java can not be overridden.
- Always remember that your instance variables will be either mutable or immutable. Identify them and return new objects with copied content for all mutable objects (object references). Immutable variables (primitive types) can be returned safely without extra effort.
Why there are two Date classes; one in java.util and another in java.sql package?
A java.util.Date represents date and time of day, a java.sql.Date only represents a date. The complement of java.sql.Date is java.sql.Time, which only represents a time of day. The java.sql.Date is a subclass (an extension) of java.util.Date. So, what changed in java.sql.Date:
– toString() generates a different string representation: yyyy-mm-dd
– a static valueOf(String) methods to create a date from a string with above representation
– the getters and setter for hours, minutes and seconds are deprecated
The java.sql.Date class is used with JDBC and it was intended to not have a time part, that is, hours, minutes, seconds, and milliseconds should be zero… but this is not enforced by the class.
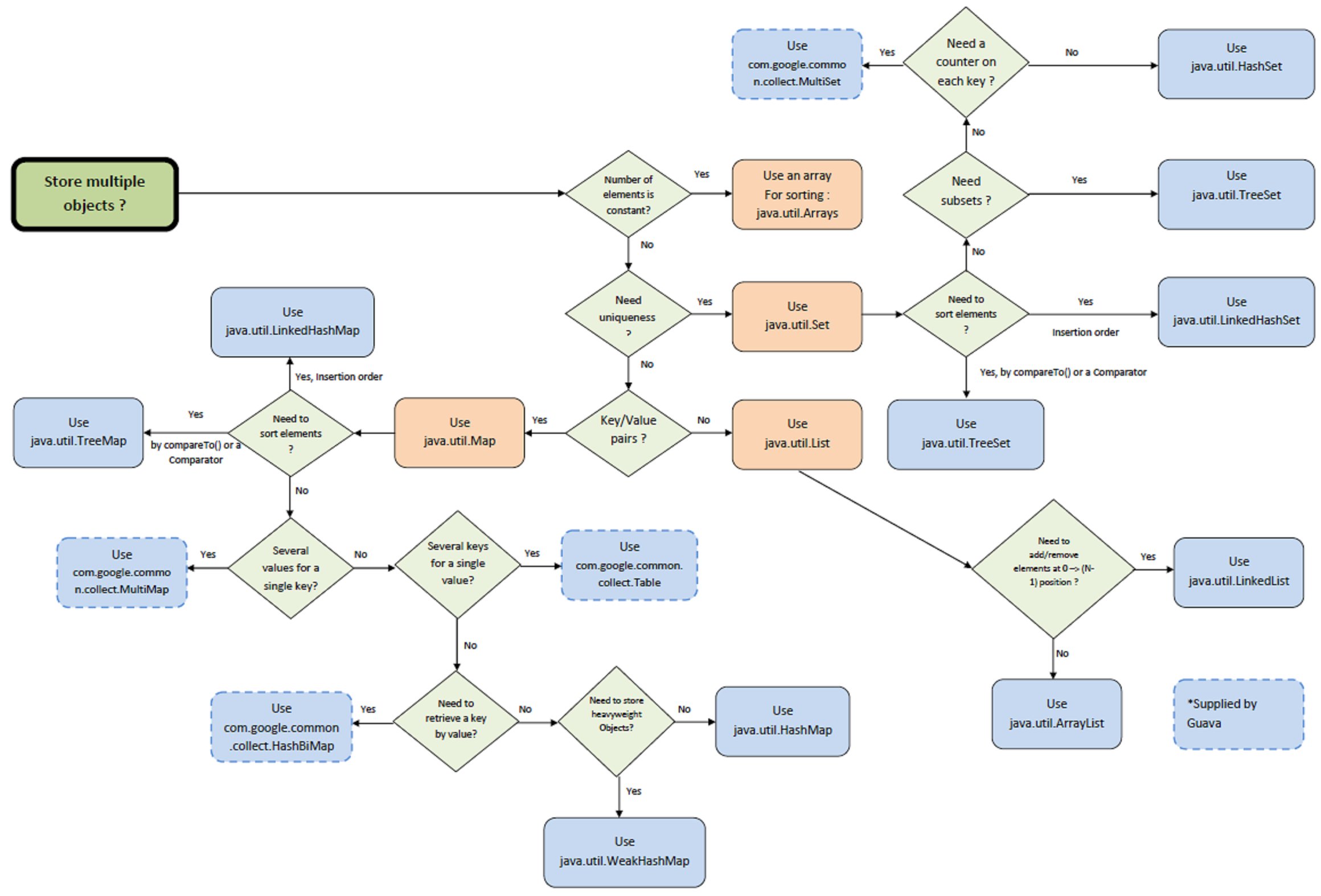
Choose Collection