HTTP and Servers
HTTP
Browsers effectively only speak one language to request information: the HyperText Transfer Protocol (HTTP). This means that a browser must talk to a server that also speaks HTTP and can respond to the browser's requests for information.
HTTP Networking
All computer networking at the software level is based on an abstraction called a socket. Sockets represent a specific open connection to another computer. A server starts listening for incoming connections, and a client asks to open a new connection. Connections are defined using numeric dot-separated IP addresses like 192.168.0.255, and an additional numeric port numbers like 8080. An individual IP address segment can be from 0-255, and port numbers range from 0-65535. Think of an IP address as a street address for an apartment building, and a port number as a specific room in that building. Any data can be sent over a socket - binary or text - it's all just bytes.
Plain HTTP is an unencrypted protocol. HTTP Secure (HTTPS) is the same content, but encrypted before being sent.
Standardized networking protocols use specific well-known port numbers. Plain HTTP defaults to port 80, and HTTPS defaults to port 443. So, an address of http://192.168.0.255 implies port 80, and https://192.168.0.255 implies port 443. Other ports are frequently used depending on project setup. For example, many web server applications listen on port 8080 or 3000 in a development environment, so in that case you would use an address like http://192.168.0.255:3000 as the destination for an HTTP connection.
Since numeric URLs are hard to remember, and a site may be made up of many systems working together, the Domain Name System (DNS) maps text name URLs like www.google.com to a specific set of numeric IP addresses.
A URL like http://www.example.com:8080/some-page?id=42#intro can be split into multiple pieces:
- protocol: http://
- subdomain: www
- domain name: example.com
- port: 8080
- path: some-page
- query parameters: ?id=42
- fragment: #intro
HTTP Requests and Responses
HTTP is a plain-text, "stateless", request/response-based protocol. In other words:
A client application has to open a connection to the server and send a request using a text-based format The server then parses the request, runs code to process and handle the request appropriately, and sends back a text-based response. Once the response has been sent, it closes the open socket connection. Each request/response is an individual transaction between a client and a server, and by default there is no correlation between separate requests Both requests and responses may also contain binary data, but the HTTP-related contents of the request and response are readable text instructions.
A typical HTTP request looks like:
GET https://www.example.com/description.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) Chrome/16.0.912.75 Safari/535.7
Accept: text/html,application/xhtml+xml
Referer: http://www.google.com/url?&q=example
Accept-Language: en-US,en
The first line of the request is broken down into three pieces:
- The HTTP method or verb, such as GET or POST
- The path of the request
- The HTTP protocol version
After that, the request may contain additional headers. Each header is a piece of metadata that the client can include so that the server better understands what kind of information is being requested.
The request may also include a body after the headers, with additional data.
Responses follow the same structure:
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Server: Apache/2.4
Date: Sun, 01 Nov 2020 16:38:23 GMT
Content-Length: 17151
<html>
<head>
<title>Page Title Here</title>
</head>
<body>
Content here
</body>
</html>
The first line contains:
The HTTP protocol version The HTTP status code, in a numeric form The HTTP status reason, in a text form That is followed by additional header lines containing metadata about the response, including the total byte size of the body. Finally, the response includes the actual body contents.
HTTP Headers
There are dozens of header fields that can be sent over HTTP, and both clients and servers can send additional arbitrary headers they've defined. Some of the most common headers are:
- Requests
- User-Agent: a string describing the specific type and version of the client
- Cookie: a small piece of data previously attached by the server to help track this client
- Referer: URL of the previous page where a link was clicked
- Responses
- Content-Length: size of the response in bytes
- Location: redirect request to a new URL
- Set-Cookie: creates a new cookie value
- Both
- Content-Type: name of the format used in the request / response body
HTTP Methods
The HTTP protocol specifies several possible methods or verbs. Each HTTP method represents a different type of request intent:
GET: the client wants to retrieve information POST: the client wants to create or update data on the server PUT: the client wants to update or replace data on the server DELETE: the client wants to delete some data on the server
Each HTTP method has different variations in how the request is formatted, and when/why it should be used by a client. In addition, some types of requests can be treated as "idempotent" (can be done many times without causing additional changes).
- GET Requests
GET requests are used to retrieve information from the server, based on a specific URL. GET requests do not contain a request body. However, clients may include additional data as query parameters options attached to the main URL. Query params start with a ?, and are formatted as key=value pairs separated by ampersands: /endpoint?a=1&b=stuff. Spaces and special characters in URLs may need to be URL-encoded, where the original value is replaced by a % and a number: ?a=Some Value might become ?a=Some%20Value.
Since GET requests are only used for retrieving data, servers should not update data in response to a GET. This means it should be safe to make the same GET request multiple times without causing side effects.
- POST Requests
POST requests are used to tell the server to update some data or process some information. POSTs typically include all relevant information in the body of the request, and rarely include query params.
POST request bodies typically use a few common formats
"Form-encoded": the same key=value structure as query parameters, but in the body of a POST "Multi-part form data": a delimited format that splits the body into sections "JSON": a string representation of JavaScript data structures like objects and arrays
- PUT Requests
PUT requests are very similar to POST requests. Both involve sending data to the server with an intent to update. The intended difference is that a PUT is intended to create or replace a value, while a POST is intended to create or update a value. Conceptually, a PUT should be safe to do multiple times in a row, while a POST is likely to cause something to happen separately for each request.
- PATCH Requests
PATCH requests are also similar to PUT requests, but the intent is to send a partial representation of an item, while PUT is meant to send the complete representation of an item.
- DELETE Requests
DELETE requests are used to ask a server to delete some data. Conceptually, it should be safe to make a DELETE request multiple times - if a value is already gone, the server ought to ignore the request.
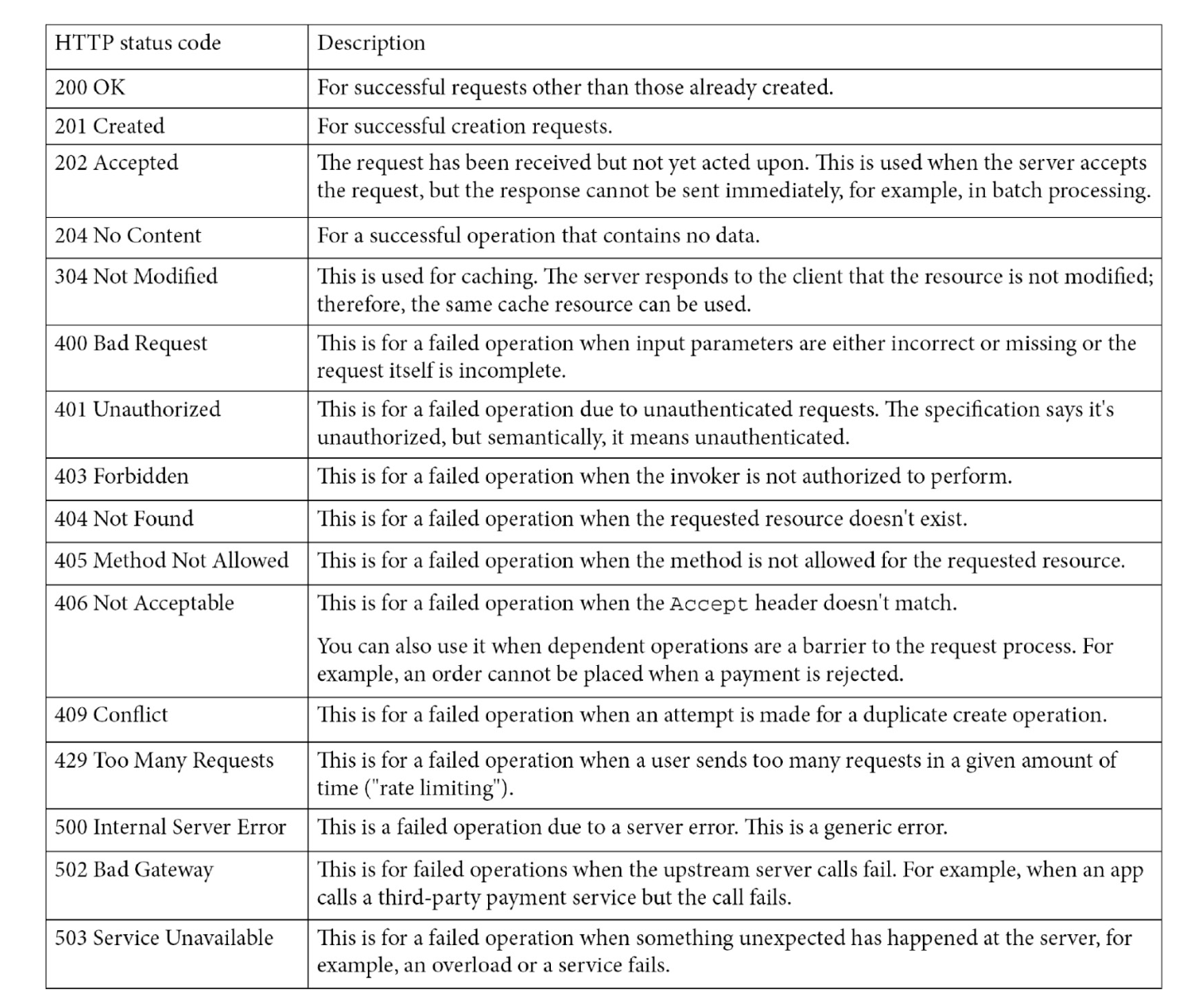
HTTP Status Codes
All HTTP responses include a numeric status code, along with a text "reason" string that describes the status code value. Status codes are 3-digit numbers, grouped into these ranges:
- 1xx: Informational
- 2xx: Successful
- 3xx: Redirection
- 4xx: Client error
- 5xx: Server error
Common HTTP status codes include:
Cookies
HTTP is inherently "stateless" by default, but servers normally want some way to correlate a specific client's identity between multiple requests. For example, if I log into a forum site, the server should remember that I'm logged in as I browse through different pages.
The HTTP spec allows servers to include Set-Cookie headers in responses with specific keys and values:
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
Whenever a client makes future requests to that server, the cookie values will be automatically included in the request:
GET /sample_page.html HTTP/2.0
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
Typically, a server will set a "session cookie" that contains some unique ID value, and map that unique ID internally to additional data (such as "session ID 12345 is actually user mark"). That way, each time a request is made, the server can look up the additional data needed to handle that specific user ("Request is for /messages, and the session data says the user is mark - query the database for all messages sent to user mark").
Servers
The word "server" has multiple related meanings depending on the context:
- The application that opened up a socket to listen for incoming requests
- An application that is specifically able to handle HTTP requests and send back responses
- The physical or virtual machine that is running that server application
Here, we're going to focus on the "HTTP request handling application" meaning.
Basic HTTP Request Processing
Every HTTP server application starts handling a request by accepting an incoming socket connection, and parsing the request contents into some internal data structure. The server then inspects the HTTP request path and the method to determine the intent of the request.
Depending on how the server has been written and configured, it will then handle the request by doing some combination of:
- Reading files from disk
- Connecting to a database and loading / updating data
- Updating session tracking information internally
- Running developer-specified logic
Ultimately, the server application will fill out an HTTP response message based on all of the processing, write it to the socket, and close the connection.
Routing
Routing refers to determining what code to run based on a request URL. Servers normally use a combination of the HTTP request method and the request URL path to determine what code should handle a request. For example, GET /users might be handled by one specific function, POST /users by a second function, and GET /images/header.png by another function.
Servers typically use a convention that if /some-folder/index.html exists, it will be used as the response contents for a request to GET /some-folder/. This pattern has carried over into many other areas as well. For example, a server written using the PHP language might use /some-folder/index.php to handle requests, and the Node.js CommonJS module format will handle an attempt to load require('some-folder') by opening some-folder/index.js if it exists.
Static Files
Many HTTP requests are asking for the server to return a copy of a specific file, such as GET /images/header.png or GET /app/index.html. A server will usually handle these by mapping URLs to a specific set of folders on disk, and checking to see if a file by that name exists in the specific folder path. If it does, the server will immediately handle the request by reading the entire file from disk and returning its contents as the body of the response.
Since these files on disk typically do not change often, they are known as static files. Serving static files is a baseline capability that all HTTP server applications can do, and most web server frameworks provide a built-in mechanism for automatically serving files from a designated folder. There are many sites and tools which only host and serve static files - a user just needs to upload their files, and the site is already configured to serve them automatically.
Dynamic Server Application Logic
However, servers also need to respond to incoming requests by running additional logic written by a developer. The exact syntax and techniques used to define server logic vary widely across languages and server application frameworks, but they all share some common aspects. A typical web application server framework will allow the developer to:
- Specify which HTTP method is being handled
- Specify what URL routes are being handled
- Read an object representing the parsed HTTP request, which will contain fields with all the headers, other metadata, and body contents
- Interact with an object representing the in-progress HTTP response, which will contain fields and methods to help generate the final response contents
Many web app frameworks also implement some form of middleware, which are individual chunks of logic that are combined together. Each individual middleware typically has a specific purpose, such as adding session info to the request based on a cookie. The combined middleware then form a pipeline of preprocessing steps that are executed on every incoming request before the request is handled by the specific application logic.
The request handling code may then use whatever logic it wants to dynamically generate a response. The handler logic might:
- Check the URL and HTTP method
- Check cookies for a session ID and look up a user's details internally
- Read query parameters
- Extract data from a request body
- Connect to a database to retrieve information
- Run some calculations
- Update the database based on the calculations or the request contents
- Construct an HTML document or a JSON data structure
- Send that content back as the response body
Response Formats
Servers can send back any data they want in a response, but most responses are sent back with one of a few common formats:
- HTML: the standard markup language that describes the structure and content of a web page
- CSS: the standard styling language used to define the appearance of a web page
- JSON: a text-based data format based on the syntax for JavaScript objects, arrays, and primitive values
- XML: a customizable text-based data format based on nested tags, similar to HTML
- Actual static files (images, JavaScript files, etc)
For data, JSON has become the de-facto standard data transfer format.